blogs
论文笔记_Person Re-identification: Past, Present and Future[综述]
Abstract
Person re-identification (re-ID) has become increasingly popular in the community due to its application and research significance. It aims at spotting a person of interest in other cameras. In the early days, hand-crafted algorithms and small-scale evaluation were predominantly reported. Recent years have witnessed the emergence of large-scale datasets and deep learning systems which make use of large data volumes. Considering different tasks, we classify most current re-ID methods into two classes, i.e., image-based and video-based; in both tasks, hand-crafted and deep learning systems will be reviewed. Moreover, two new re-ID tasks which are much closer to real-world applications are described and discussed, i.e., end-to-end re-ID and fast re-ID in very large galleries. This paper: 1) introduces the history of person re-ID and its relationship with image classification and instance retrieval; 2) surveys a broad selection of the hand-crafted systems and the large-scale methods in both image- and video-based re-ID; 3) describes critical future directions in end-to-end re-ID and fast retrieval in large galleries; and 4) finally briefs some important yet under-developed issues.
由于其应用和研究意义,Person re-ID 变得越来越流行,它的目的是在其他照片或视频中查出我们感兴趣的人。在早期,研究主要是基于传统算法,近年来主要是利用大数据集和深度学习的方法。考虑到任务不同,文章将现有的re-ID方法分为两类:基于图像和基于视频,并分别对这两种分类基于传统算法和深度学习的方法进行说明。同时,讨论了两个接近真实应用的新re-ID任务:端到端(End-to-end)的re-ID和在大数据中的快速re-ID.这篇论文:1)介绍了Person re-ID的历史,及与图像分类(image classfication)和实例检索(instance retrievial)的关系。2)详细介绍了基于图像和视频的传统算法和深度学习re-ID的方法。3)指出端到端(End-to-end)的re-ID和在大数据中的快速检索(fast retrieval)是未来的主要趋势。4)简要介绍了一些其他重要但尚未解决的问题。
1 INTRODUCTION
ACCORDING to Homer (Odyssey iv:412), Mennelaus was becalmed on his journey home from the Trojan War; He wanted to propitiate the gods and return safely home. He was told that he should capture Proteus and force him to reveal the answer. Although Proteus transformed to a lion, a serpent, a leopard, water and also a tree, Mennelaus then succeeded in holding him as he emerged from the sea to sleep among the seals. Proteus was finally compelled to answer to him truthfully.
荷马史诗 (Odyssey iv:412),Mennelaus 被告知,如果想要众神息怒并平安回家,就要在特洛伊战争的回家路上抓到 Proteus,让他告诉自己躲避的方法。虽然Proteus变成了狮子,巨蛇,豹,甚至水和大树,Mennelaus最终还是在海边的海豹群中抓住了他,并知晓了自己平安回家的方法。
Perhaps this is one of the oldest stories about re-identifying a person even after intensive appearance changes. In 1961, when discussing the relationship between mental states and behavior, Alvin Plantinga [1] provided one of the first definitions of re-identification: “To re-identify a particular, then, is to identify it as (numerically) the same particular as one encountered on a previous occasion”.
这大概是关于重识别最古老的故事之一,1961年, 在讨论思想状态和行为之间的关系时,Alvin Plantinga [1] 给重识别下了第一个定义:“To re-identify a particular, then, is to identify it as (numerically) the same particular as one encountered on a previous occasion”.
Person re-identification had thus been studied in various research and documentation areas such as metaphysics [1], psychology [2], and logic [3]. All these works are grounded on Leibniz’s Law which claims that “there cannot be separate objects or entities that have all their properties in common.”
In the modern computer vision community, the task of person re-ID shares similar insights with the old times. In video surveillance, when being presented with a person-of-interest (query), person re-ID tells whether this person has been observed in another place (time) by another camera. The emergence of this task can be attributed to 1) the increasing demand of public safety and 2) the widespread large camera networks in theme parks, university campuses and streets, etc. Both causes make it extremely expensive to rely solely on brute-force human labor to accurately and efficiently spot a person-of-interest or to track a person across cameras.
Technically speaking, a practical person re-ID system in video surveillance can be broken down into three modules, i.e., person detection, person tracking, and person retrieval. It is generally believed that the first two modules are independent computer vision tasks, so most re-ID works focus on the last module, i.e., person retrieval. In this survey, if not specified, person re-ID refers to the person retrieval module. From the perspective of computer vision, the most challenging problem in re-ID is how to correctly match two images of the same person under intensive appearance changes, such as lighting, pose, and viewpoint, which has important scientific values. Given its research and application significance, the re-ID community is fast growing, evidenced by an increasing number of publications in the top venues (Fig. 1).
从技术上讲,实际视频监控系统的person re-ID系统可分为三个模块:人员检测(person detection),人员跟踪(person tracking),和 人员检索(person retrieval)。一般认为前两个任务是独立的计算机视觉任务,所以大多数re-ID主要的工作还是最后一个模块,即人员检索(person retrieval)。在本论文中,如没有特别声明,人员重识别(Person re-ID)指的是人员检索(person retrieval).从计算机视觉的角度来看,如何在光线、姿势、视角等强烈的外观变化下正确匹配同一个人的两幅图像是re-ID中最具挑战性的问题,也具有重要的科学价值。鉴于其研究和应用的重要性,re-ID的研究也在快速的增长,发表在重要期刊中的论文也越来越多[图1]。
1.1 Organization of This Survey
Some person re-ID surveys exist [4], [5], [6], [7]. In this survey, we mainly discuss the vision part of re-ID, which is also a focus in the community, and refer readers to the camera calibration and view topology methods in [5]. Another difference from previous surveys is that we focus on different re-ID subtasks currently available or likely to be visible in the future, instead of very detailed techniques or architectures. Special emphasis is given deep learning methods, end-to-end re-ID and very large scale re-ID, which are currently popular topics or reflect future trends. This survey first introduces a brief history of person re-ID in Section 1.2 and its relationship with classification and retrieval in Section 1.3. We then describe previous literature in image-based and video-based person re-ID in Section 2 and Section 3, respectively. Both sections categorize methods into hand-crafted and deeply-learned systems. In Section 4, since the relationship between detection, tracking, and re-ID has not been extensively studied, we will discuss several previous works and point out future research emphasis. In Section 5, large-scale re-ID which resorts to state-of-the-art retrieval models will be introduced, which is also an important future direction. Some other open issues will be summarized in Section 6, and conclusions will be drawn in Section 7.
参考文献[4][5][6][7]是一些关于Person re-ID的综述。在本篇论文中,作者主要讨论re-ID的视觉部分,这也是大家关注的焦点,推荐读者阅读参考文献[5]有关摄像机校准和拓扑视图的方法。与其他综述文献的另一个不同是,作者关注于当前和未来可能出现的re-ID的新idea,而不是非常详细的技术或结构。特别强调深度学习的方法,端到端(End to end)的re-ID和大数据中的re-ID,这也是当前和未来的发展趋势。1.2节介绍re-ID的历史,1.3节介绍re-ID与分类和检索的关系,第2节和第3节分别介绍了基于图像和视频的Person re-ID的一些论文,每一类都分为基于传统算法和深度学习的方法。第4节回顾了检测、跟踪以及re-ID相关的技术,并指出未来研究重点。第5节介绍代表当前最好的检索模型:large-scale re-ID,这也是未来研究的方向。第6节介绍了一些open issues。第7节是结论部分。
1.2 A Brief History of Person Re-ID
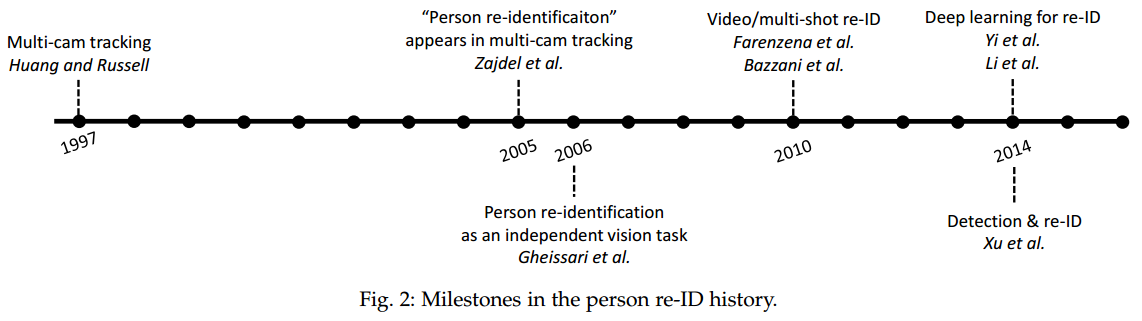
Person re-ID research started with multi-camera tracking [8]. Several important re-ID directions have been developed since then. In this survey, we briefly introduce some milestones in person re-ID history (Fig. 2)
-
Multi-camera tracking.
In the early years, person re-ID, as a the term without being formally raised, was tightly twined with multi-camera tracking, in which appearance models were integrated with the geometry calibration among disjoint cameras. In 1997, Huang and Russell [9] proposed a Bayesian formulation to estimate the posterior of predicting the appearance of objects in one camera given evidence observed in other camera views. The appearance model includes multiple spatial-temporal features such as color, vehicle length, height and width, velocity, and time of obser-vation. A comprehensive survey of multi-camera tracking can be accessed in [8].
-
Multi-camera tracking with explicit “re-identification”.
To our knowledge, the first work on multi-camera tracking where the term “person re-identification” is proposed, was published in 2005 by Wojciech Zajdel, Zoran Zivkovic and Ben J. A. Kr ̈ ose from the University of Amsterdam [10]. In their ICRA’05 paper entitled “Keeping track of humans: Have I seen this person before?”, Zajedel et al. aims to “re-identify a person when it leaves the field of view and re-enters later”. In their method, a unique, latent label is assumed for every person, and a dynamic Bayesian network is defined to encode the probabilistic relationship between the labels and features (color and spatial-temporal cues) from the tracklets. The ID of an incoming person is determined by the posterior label distributions computed by an approximate Bayesian inference algorithm.
-
The independence of re-ID (image-based).
One year later in 2006, Gheissari et al. [11] employed only the visual cues of persons after a spatial-temporal segmentation algo-rithm for foreground detection. Visual matching based on color and salient edgel histograms is performed by either an articulated pedestrian model or the Hessian-Affine interest point operator. Experiments are conducted on a dataset with 44 persons captured by 3 cameras with moderate view overlap. Note that, although Gheissari et al. [11] design a spatial-temporal segmentation method using the video frames, neither the feature design nor matching processes use the video information, so we classify [11] into image-based re-ID. This work [11] marks the separation of person re-ID from multi-camera tracking, and its beginning as an independent computer vision task.
-
Video-based re-ID.
Initially intended for tracking in videos,mostre-IDworksfocusonimagematchinginstead.In the year 2010, two works [12], [13] were proposed for multi-shot re-ID, in which frames are randomly selected. Color is a common feature used in both works, and Farenzena et al. [13] additionally employ a segmentation model to detect the foreground. For distance measurement, both works calculate the minimum distance among bounding boxes in two image sets, and Bazzani et al. further use the Bhattacharyya distance for the color and generic epitome features. It is shown that using multiple frames per person effectively improves over the single-frame version [12], [13] and that re-ID accuracy will saturate as the number of selected frames increases [12].
-
Deep learning for re-ID.
The success of deep learning in image classification [14] spreads to re-ID in 2014, when Yi et al. [15] and Li et al. [16] both employ a siamese neural network [17] to determine if a pair of input images belong to the same ID. The reason for choosing the siamese model is probably that the number of training samples for each identity is limited (usually two). Aside from some variations in parameter settings, the main differences are that [15] adds an additional cost function in the network, while [16] uses a finer body partitioning. The experimental datasets do not overlap in [15] and [16], so the two methods are not directly comparable. Although its performance is not stable yet on the small datasets, deep learning methods has since become a popular option in re-ID
-
End-to-end image-based re-ID.
While a majority of works use hand-cropped boxes or boxes produced by a fixed detector in their experiments, it is necessary to study the impact of pedestrian detectors on re-ID accuracy. In 2014, Xu et al. [18] addressed this topic by combining the detection (commonness) and re-ID (uniqueness) scores. It is shown that on the CAMPUS dataset, jointly considering detection and re-ID confidence leads to higher person retrieval accuracy than using them separately.
1.3 Relationship with Classification and Retrieval

Person re-ID lies inbetween image classification [14] and instance retrieval [19] in terms of the relationship between training and testing classes (Table 1). For image classification, training images are available for each class, and testing im-ages fall into these predefined classes, denoted as previously “seen” in Table 1. For instance retrieval, usually there is no training data because one does not know the content of the query in advance and the gallery may contain various types of objects. So the training classes are “not available” and the testing classes (queries) are denoted as previously “unseen”.
Compared to image classification, person re-ID is similar in that the training classes are available, which includes images of different identities. Person re-ID is also similar to instance retrieval in that the testing identities are unseen: they do not have overlap with the training identities, except that both training and testing images are of pedestrians.
As a consequence, person re-ID can be positioned to take advantage of both classification and retrieval. On the one hand, using training classes, discriminative distance metrics [20] or feature embeddings [16], [21] can be learned in the person space. On the other hand, when it comes to retrieval, efficient indexing structures [22] and hashing techniques [23] can be beneficial for re-ID in a large gallery. In this survey, both effective learning and efficient retrieval approaches will be introduced or pointed out as important future directions.
2 IMAGE-BASED PERSON RE-ID
Since the work by Gheissari et al. in 2006 [11], person re-ID has mostly been explored using single images. Let us consider a closed-world toy model, in which G is a gallery (database) composed of N images, denoted as $ $. They belong to N different identities 1,2,……,N. Given a probe (query) image q, its identity is determined by:
\[i^* = argmax_{i \epsilon 1,2,……,N} sim(q,g_i)\]2.1 Hand-crafted Systems
It is apparent from Eq. 1 that two components are necessary for a toy re-ID system, i.e., image description and distance metrics.
-
2.1.1 Pedestrian Description
-
2.1.2 Distance Metric Learning